项目源码地址
Augu1sto/leet2md: 将leetcode.cn上面的部分leetbook和solution题解保存为markdown文件 (github.com)
需求分析
在阅读Leetcode题解、Leetbook(如图解算法数据结构 - LeetBook - 力扣(LeetCode)全球极客挚爱的技术成长平台 (leetcode-cn.com))要做markdown笔记时,复制粘贴总会出现格式混乱/公式渲染等问题。经过一阵尝试和分析之后,打算直接用python爬取整个网页内容,将文章保存存为markdown格式再进行编辑。
网页分析
以图解算法数据结构 - LeetBook - 力扣(LeetCode)全球极客挚爱的技术成长平台 (leetcode-cn.com)为例
通过查看网页源码发现,文章的具体内容是动态加载的,【F12】-网络-Fetch/XHR-刷新,可以查看捕获的数据包。
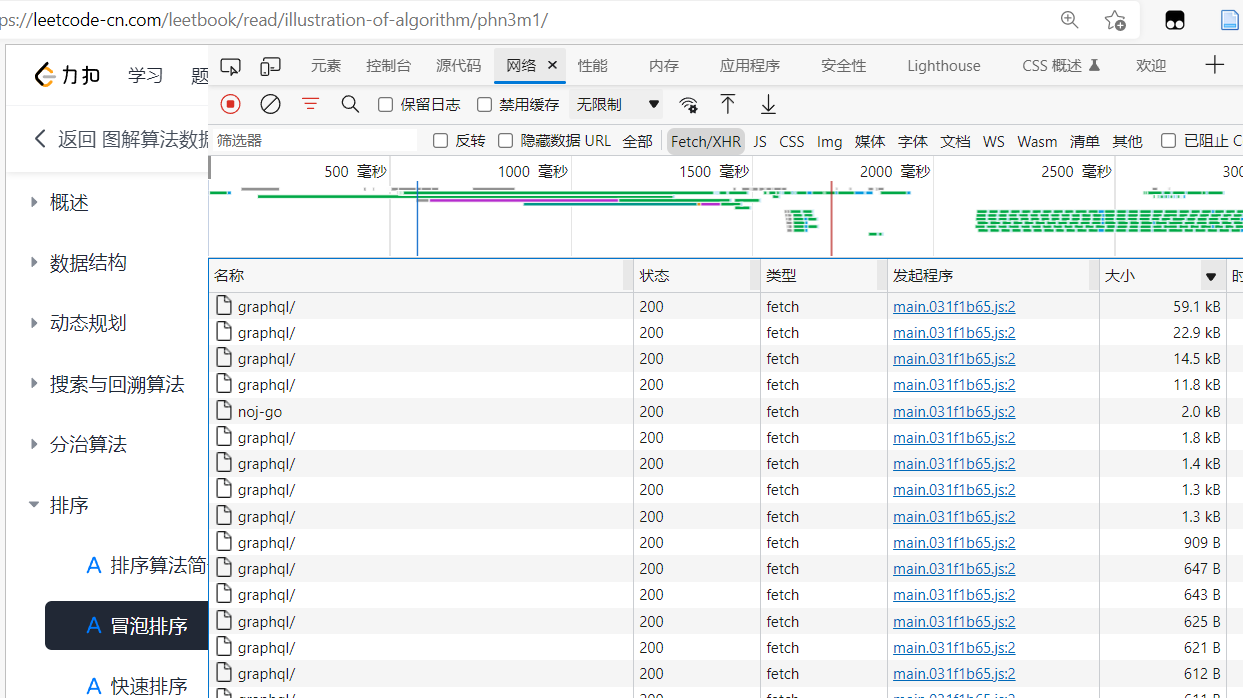
按大小进行排序,在预览里可以看到每个数据包大致的内容,如下图的数据包大致就是整本书的一个目录索引
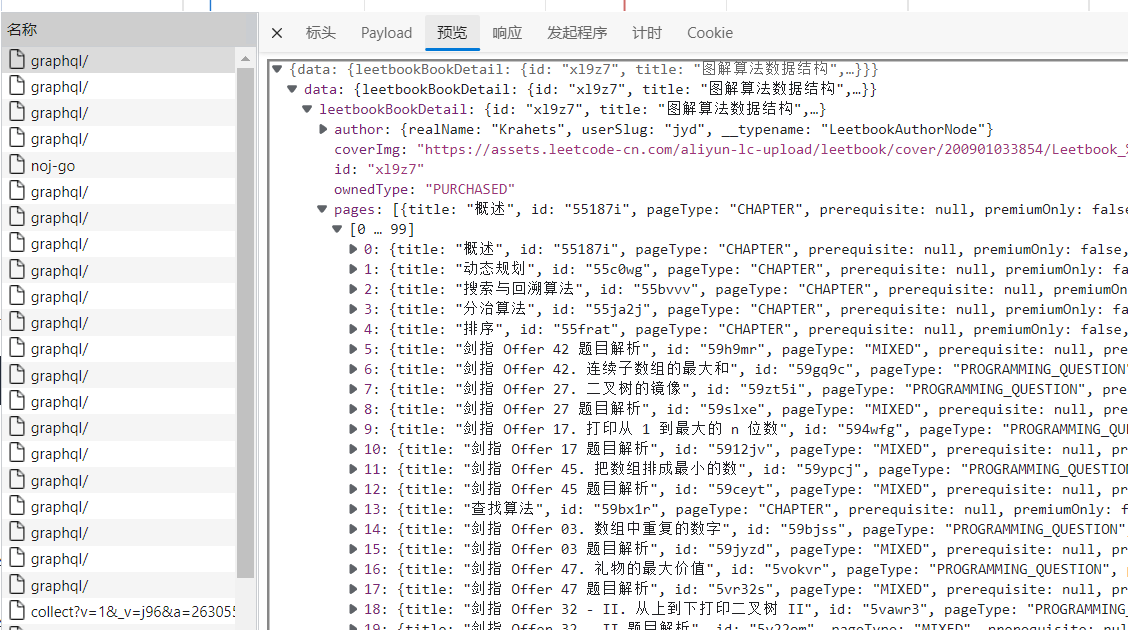
看到大概第4个graphql的时候,就看到目标文章了
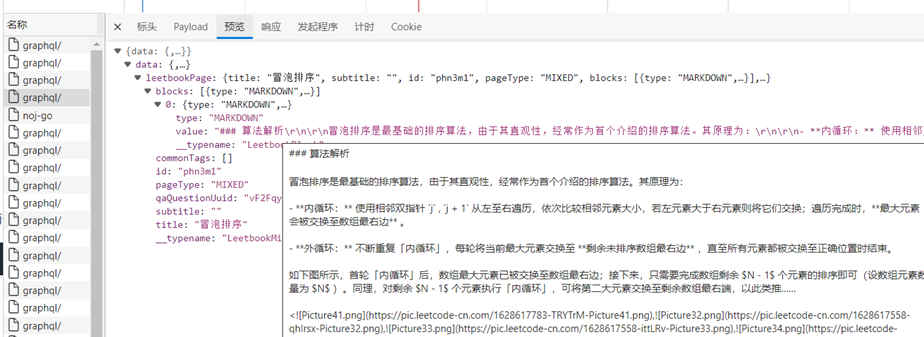
注意这里的type是MARKDOWN,value的内容就是Markdown格式的文章。而有的leetbook的type是其他类型比如HTML,这里就不考虑、不处理了。
接下来的工作重点就是将这个value值爬下来。
GraphQL
GraphQL 是一种针对 Graph(图状数据)进行查询特别有优势的 Query Language(查询语言),所以叫做 GraphQL。
GraphQL 既是一种用于 API 的查询语言也是一个满足你数据查询的运行时。 GraphQL 对你的 API 中的数据提供了一套易于理解的完整描述,使得客户端能够准确地获得它需要的数据,而且没有任何冗余,也让 API 更容易地随着时间推移而演进,还能用于构建强大的开发者工具。
GrapgQL是Facebook发明的,在Facebook/Github/coursera/…中有广泛应用。
GraphQL的使用与学习主要集中在描述与请求上,本文设计的问题应该就是要请求查询,可以参考GraphQL Code Libraries, Tools and Services进行学习。
但文章中选择直接利用requests实现。
request实现Leetbook中markdown类型文章爬取
构造POST请求
1
| response = requests.request("POST",url,headers=headers,data=json.dumps(payload))
|
url
在前文提到的捕获的数据包中查看标头

所需的url即为https://leetcode-cn.com/graphql/
可以发现前面是https://leetcode-cn.com/,也就是整个leetcode网站的url。
据我观察,大部分url都是[根站点网址]/graphql的形式
即请求标头这一栏,其中最为重要的是cookie、origin、refer三个字段
cookie:包含了你的登录ID、session等信息,直接复制下来就可以origin:网站根地址,这里就是https://leetcode-cn.com/refer:你要爬的文章的地址
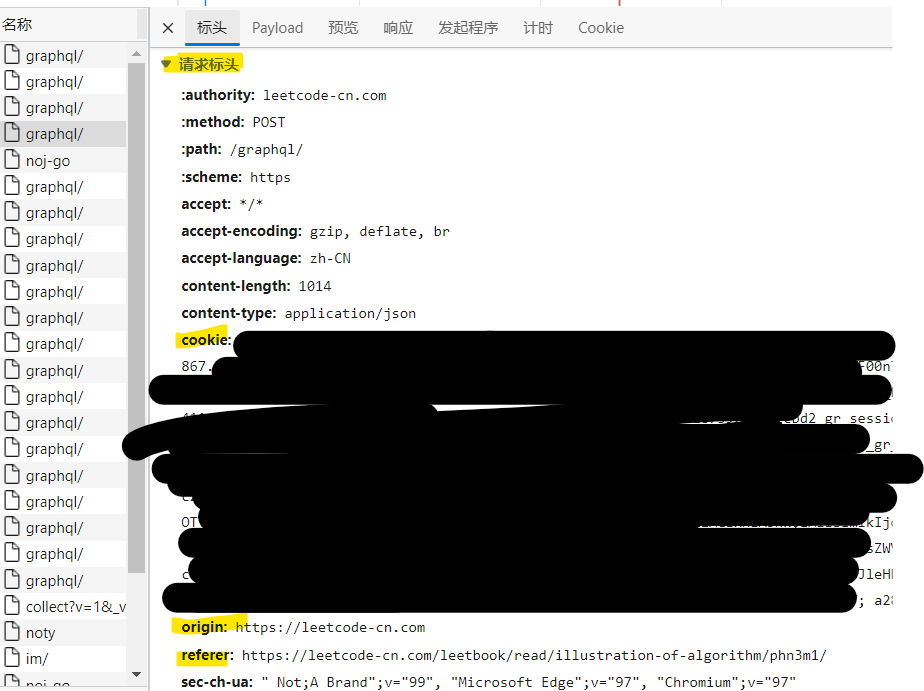
payload
选择payload,右击-复制值即可
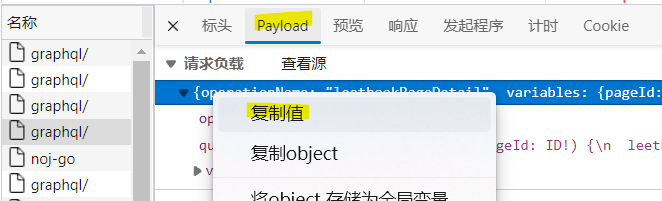
注意, payload的variables里有一项pageId,即为文章网址最后的一串字符,同时在第一个graphql中也有记录(见下图),我们可以通过这种方式来爬取整本书的内容。
解析内容
对response.content进行解码,即可获得预览中的数据
首先分析该文章是否是markdown形式
1
2
| if b["data"]["leetbookPage"]["blocks"][0]["type"]!='MARKDOWN':
print("非markdown类型\n")
|
如果是,我们即可提取出内容
1
2
| mdtext = b["data"]["leetbookPage"]["blocks"][0]["value"]
mdtitle = b["data"]["leetbookPage"]["title"]
|
源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| # @author: augu1sto
# blog: augu1sto.gitee.io
# 将leetbook存为markdown(仅适用于源网页是markdown类型的书籍)
# 例 图解算法数据结构 https:
import requests
import json
url = "https://leetcode-cn.com/graphql/"
headers = {
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN',
'content-type': 'application/json',
'cookie': '',
'origin': 'https://leetcode-cn.com',
'referer': '',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55',
}
payload = {"operationName":"leetbookPageDetail",
"variables":{"pageId":""},
"query":"query leetbookPageDetail($pageId: ID!) {\n leetbookPage(pageId: $pageId) {\n title\n subtitle\n id\n pageType\n blocks {\n type\n value\n __typename\n }\n commonTags {\n nameTranslated\n name\n slug\n __typename\n }\n qaQuestionUuid\n ...leetbookQuestionPageNode\n __typename\n }\n}\n\nfragment leetbookQuestionPageNode on LeetbookQuestionPage {\n question {\n questionId\n envInfo\n judgeType\n metaData\n enableRunCode\n sampleTestCase\n judgerAvailable\n langToValidPlayground\n questionFrontendId\n style\n content\n translatedContent\n questionType\n questionTitleSlug\n editorType\n mysqlSchemas\n codeSnippets {\n lang\n langSlug\n code\n __typename\n }\n topicTags {\n slug\n name\n translatedName\n __typename\n }\n __typename\n }\n __typename\n}\n"}
site_url = input("site_url: ")
page_id = input("page_id: ")
cookie = input("cookie: ")
headers['referer']= site_url
payload['variables']['pageId'] = page_id
headers['cookie'] = cookie
response = requests.request("POST",url,headers=headers,data=json.dumps(payload))
a=response.content.decode()
b=json.loads(a)
if b["data"]["leetbookPage"]["blocks"][0]["type"]!='MARKDOWN':
print("非markdown类型\n")
else:
mdtext = b["data"]["leetbookPage"]["blocks"][0]["value"]
mdtitle = b["data"]["leetbookPage"]["title"]
with open(mdtitle+'.md','w+',encoding='utf-8') as f:
f.write("# "+mdtitle+"\n\n")
f.write(mdtext)
|
request实现Leetcode中官方题解的爬取
通过类似的分析思路,我们也可以爬取leetcode指定链接的题解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| # @author: augu1sto
# blog: augu1sto.gitee.io
# 将leetcode的solution存为markdown
# 仅测试了官方题解
import requests
import json
url = "https://leetcode-cn.com/graphql/"
headers = {
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN',
'content-type': 'application/json',
'cookie': '',
'origin': 'https://leetcode-cn.com',
'referer': '',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55',
}
payload = {"operationName":"solutionDetailArticle",
"variables":{"slug":"","orderBy":"DEFAULT"},
"query":"query solutionDetailArticle($slug: String!, $orderBy: SolutionArticleOrderBy!) {\n solutionArticle(slug: $slug, orderBy: $orderBy) {\n ...solutionArticle\n content\n question {\n questionTitleSlug\n __typename\n }\n position\n next {\n slug\n title\n __typename\n }\n prev {\n slug\n title\n __typename\n }\n __typename\n }\n}\n\nfragment solutionArticle on SolutionArticleNode {\n rewardEnabled\n canEditReward\n uuid\n title\n slug\n sunk\n chargeType\n status\n identifier\n canEdit\n canSee\n reactionType\n reactionsV2 {\n count\n reactionType\n __typename\n }\n tags {\n name\n nameTranslated\n slug\n tagType\n __typename\n }\n createdAt\n thumbnail\n author {\n username\n profile {\n userAvatar\n userSlug\n realName\n __typename\n }\n __typename\n }\n summary\n topic {\n id\n commentCount\n viewCount\n __typename\n }\n byLeetcode\n isMyFavorite\n isMostPopular\n isEditorsPick\n hitCount\n videosInfo {\n videoId\n coverUrl\n duration\n __typename\n }\n __typename\n}\n"}
site_url = input("site_url: ")
U = site_url.split('/')
if U[-1]!='':
sol_name = U[-1]
else:
sol_name = U[-2]
cookie = input("cookie: ")
headers['referer']= site_url
payload['variables']['slug'] = sol_name
headers['cookie'] = cookie
response = requests.request("POST",url,headers=headers,data=json.dumps(payload))
a=response.content.decode()
b=json.loads(a)
mdtext = b["data"]["solutionArticle"]["content"]
mdtitle = b["data"]["solutionArticle"]["title"]
with open(mdtitle+'.md','w+',encoding='utf-8') as f:
f.write("#"+mdtitle+"\n\n")
f.write(mdtext)
|
总结




