【论文阅读|TrajGen】KDD21'Generating Mobility Trajectories with Retained Data Utility
论文基本信息⁍
- 作者:Chu Cao, Mo Li(南洋理工)
- 年份:2021
- 会议/期刊:KDD
- 相关下载:
- 阅读参考:
- 开源信息: github (仓库尚在更新,未完全开源)
- 简介:提出了一种新的时空轨迹生成模型,该模型基于 GAN 与 Seq2Seq 来仿照真实轨迹生成相似的轨迹数据。
- 模型名称:TrajGen
- 数据集: real-world taxi trajectory data in Singapore.
简介⁍
提出了一种新的轨迹生成模型,该模型基于 GAN 与 Seq2Seq 来仿照真实轨迹生成相似的轨迹数据。
- 时空信息的解耦与合并
- 空间分布的图像:GAN
- 时间信息学习:Seq2Seq
- 从GAN生成的图像中提取位置并输入Seq2Seq模型以推断出连接这些位置和轨迹的适当序列轨迹。一个完全连接的ANN将时间戳分配给每个轨迹中的顺序位置。
问题定义⁍
输入:
-
历史真实轨迹集合 :
$${\tau_1,\tau_2,\tau_3,…,\tau_n}$$
- $\tau=(loc_1,loc_2,…)$
- $loc_i=(lat_i,lon_i,t_i)$
-
路网信息,表示路段集合V以及路段间的交点集合E。
$$G=(V,E)$$
输出:
-
生成的轨迹集合,其分布与原轨迹集合相似。
$${\hat\tau_1,\hat\tau_2,\hat\tau_3,…,\hat\tau_m}$$
旅行模式:
-
旅行模式反映了用户的旅行偏好,是一连串的地理上相邻的边
$${e_1\rightarrow e_2\rightarrow …\rightarrow e_n}$$
算法框架⁍

输入:Mobility Trajectories + Mobility Map
1)生成空间点,学习空间位置的分布,生成一条轨迹的空间点集合;–>DCGAN[]
2)赋予空间点顺序。对生成的空间点集合,赋予其顺序关系,使空间点集合转为空间点序列;–> map matching[25],seq2seq[32]
3)赋予每个空间点相应的时间戳信息。–>ANN
空间分布学习——生成空间点⁍
-
2D空间映射为图像(可逆)

-
将城市整个城市地图$M$进行了网格化(像素化),从而将每个轨迹点映射到了一个网格(像素)中
- 城市最小经度 $x_0=\min{longitude_M}$
- 城市最小纬度 $y_0 = \min{latitude_M}$
- 城市经度跨度 $W = \max{longtitude_M}-x_0$
- 城市纬度跨度 $H = \max{latitude_M}-y_0$
- 图片像素大小 $\mu$
-
$\tau_i\rightarrow\bar{\tau_i}$:
$$(lat_i,lon_i,t_i)\rightarrow(\frac{lon_i-x_0}{\mu},\frac{lat_i-y_0}{\mu})$$
-
$\bar{\tau_i}\rightarrow img_i$:坐标像素和周围8个像素都为黑色,其他为白色(时空位置上都很接近的块可以合并为一个)
-
-
用DCGAN来生成新的图片形式的轨迹,模拟原始轨迹的分布

-
用Harris角落检测器[15]识别生成的图像的角落,并转换为经纬度形式的位置
赋予空间点顺序⁍
在上一步,该模型生成了一条轨迹对应的、无序的轨迹空间点集合。在本步骤,这些空间点被赋予顺序,使得在此顺序下,空间点序列与真实轨迹序列相近。
- 训练模型(seq2seq): travel pattern
- 输入:Mobility Map Embedding
- 目标输出:按原始顺序排布的位置路径(Ground Truth)
数据预处理⁍
通过基于距离的路网匹配算法,将轨迹点映射到最近的路段上
-
如下图(a),点1-5首先通过路网匹配算法,映射到了i,ii,iii,iv,v五条路段上。
-
路段ID进行排序,得到图(b)的Mobility Map Embedding序列(default序列)

训练⁍

-
每条真实轨迹为Seq2Seq模型提供一个训练样本,即一对源序列和目标序列。
-
Seq2Seq模型将源序列编码为一个向量,并将向量解码为一个目标序列。通过这样一个编码器-解码器结构,Seq2Seq构建了将源序列映射到目标序列的条件概率。
-
利用GRU作为Seq2Seq模型的RNN单元,先用GRU编码器将Mobility Map Embedding序列编码为隐层表征,并用GRU解码器解码,与Ground Truth进行比较,以更新GRU模型参数。此处,各条路段初始状态下被表示为one-hot形式。
一个Seq2Seq模型被训练来学习序列信息。Seq2Seq模型的所有参数都是随机初始化的,并使用Adam优化器进行更新。我们利用GRU作为Seq2Seq模型的RNN单元,因为它比LSTM具有更高的计算效率。在Seq2Seq模型的训练过程中,我们采用了填充技术,以确保所有的输入都是相同的长度,并利用注意力机制使Seq2Seq模型强调重要路段。(Appendix A.2 Implementation)
生成⁍
给定无序的、生成的空间点集合
- 首先经过预处理,得到Mobility Map Embedding序列。
- 利用已训练完成的GRU编码器和解码器,推测这些路段的真实顺序。
- 得到路段顺序之后,相应地匹配到这些路段上的空间点顺序也可以被得到。
时序信息学习——推测时间信息⁍
通过上述两步骤,一条生成轨迹可以被表示为空间点序列: ${(lat_1,lon_1),(lat_2,lon_2),…}$
本步骤对序列中的每个点赋予时间。
1)推测第一个点的时间 $t_0$。
这一步通过ANN来实现,其输入特征为轨迹长度,以及轨迹经过的第一条匹配路段,输出为时间$t_0$。由原始真实数据训练得到模型参数。
2)为任意第i个点赋予时间 $t_i=t_0+i\times\Delta t$
$1/\Delta t$为为真实数据的采样频率 ==> 数据集的采样频率要固定
time slot $\Delta t = 15s$
结果⁍

实验⁍
- 数据集:新加坡路网以及新加坡出租车轨迹数据执行实验。
- Baseline:
- 1)Random Perturbation(RP),将原始轨迹点替换为其2km范围内的随机任一点;
- 2)Gaussian Perturbation(GP),将原始轨迹点替换为高斯分布点;
- 3)TrajGen-v。与上述方法相同,但DCGAN和Seq2Seq训练数据来自不同数据源,此处论文作者的意图是验证DCGAN和RNN可以被独立训练;
- Raw Data。提取了原始真实数据的一个子集,该方法的实验效果,表示了模型的效果上限。
- Base Data。原始的真实数据。
空间分布的相似性⁍
- Cosine相似度:把上图中的、带有轨迹点密度信息的网格矩阵向量化,并计算两向量之间的Cosine值。

上图给出了原始数据(base data)与五种方法的轨迹数据空间分布对比,以热力图形式呈现,其中每个网格代表$1km^2$ 的小区域。由于RP和GP这两个baseline被设计得较为糟糕,原始的轨迹点位置信息被完全模糊化,因此效果非常差。
-
为了克服实验的偶然因素,轨迹集合生成、以及空间分布相似度计算过程,被重复执行500次。

上图6给出了五种方法生成轨迹与真实轨迹Cosine值在500次重复实验中的分布情况(CDF:分布函数)。可以看出,即使重复实验多次,TrajGen生成轨迹的Cosine值稳定地大于0.9,效果排第二,仅次于从真实数据中选择子样本。
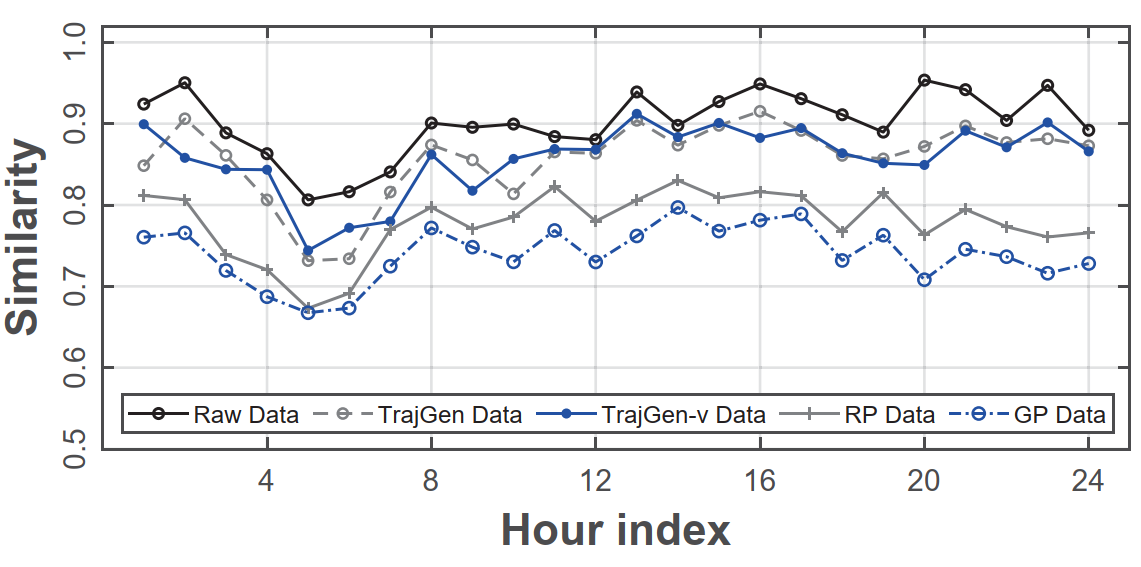
时序分布相似性⁍
-
计算各种方法与base data的分布之间的Cosine相似性
统计特征⁍
举了四种例子证明TrajGen模型可以保留统计特征。
-
到匹配路段的距离(fig.8)

-
travel distance(fig.9)
$$d_{\tau_i}=\sigma_{k=1}{m-1}{D_{mm}(loc_ki,loc_{k+1}^i)}, D_{mm}(a,b)表示a,b两点间路段的距离$$

-
每个小时的travel覆盖的范围(km2)

-
普通道路和快速道路的比例
Based on the
#taginformation in OpenStreetMap [26]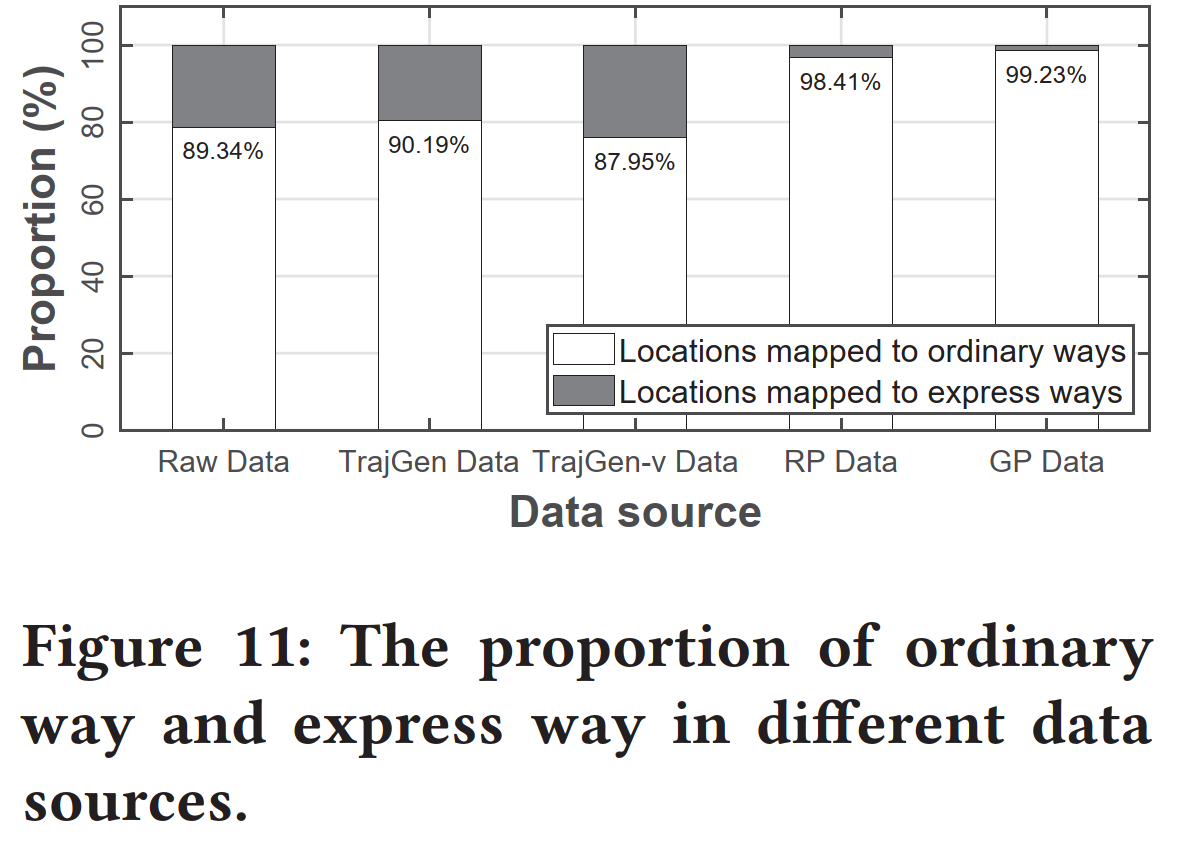
实用性⁍
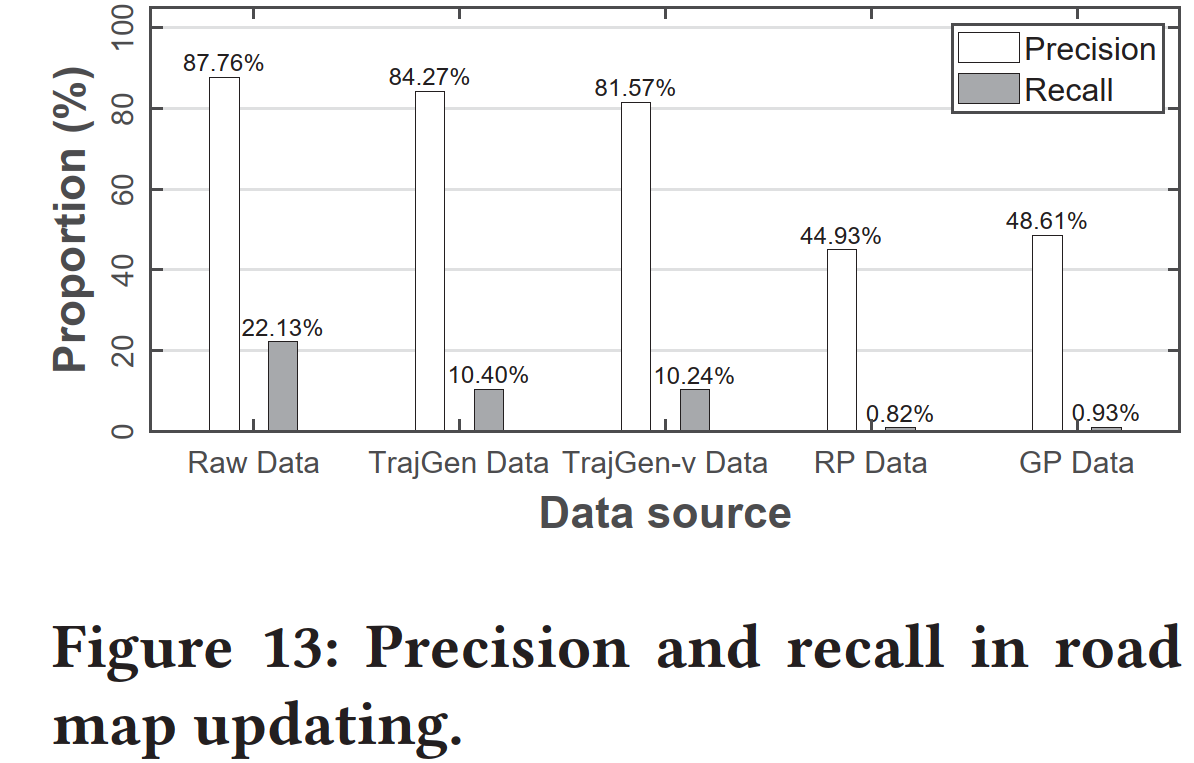
case 1:路网更新⁍
利用生成轨迹进行路网更新,测试生成轨迹是否能帮助发现未收录的路网。

如上图所示,灰色路段为原路网,黑色路段是为测试路网更新效果而被删除的路段,红色是被轨迹检测出的路段。可以发现,即使输入路网数据删除了大量路段,TrajGen仍然可以从原始轨迹中感知这些路段的存在,并生成沿着路段移动的轨迹。这从侧面体现了,在该工作的设置下,DCGAN可以捕获输入图片在局部位置频繁出现的线路形状,并在生成阶段也在这些局部位置,相应地形成同样形状的线路。
case 2:起点-终点需求估计⁍
OD估计是描述公民出行需求的经典应用。其目的是计算OD矩阵。矩阵的每个值都代表从一个地点(即原点)到另一个地点(即目的地)的旅行需求。
- 对出租车的OD需求定义为每个时间间隔内从出发地到目的地的出租车请求总数。
- 一段轨迹可能包含多个旅程journey(OD对):用在小区域内移动或停留在出租车上客站所产生的位置来区分。
- 用DBSCAN[17]算法来确定核心位置,切割多个旅程
-
通过比较OD矩阵来评估TrajGen是否保留了OD需求的效用。
-
把OD矩阵reshape成向量
-
计算Cosine相似度

总结⁍
- 这个工作主要是将轨迹的空间和时间信息进行解耦,将空间位置信息以图像的形式进行伪造的生成(DCGAN),再推断出时序信息(Seq2Seq),并合并进去
- 文中将轨迹进行了可视化处理
- 为了证明生成的轨迹的可用性,设计了非常详实的实验,有许多可以借鉴的地方
- 没有实验证明生成的轨迹的隐私性(对比TrajGAN,设计了TUL的实验)
-
相关工作
-
background部分有对GAN和seq2seq的介绍



